In this blog post we will be using Openstack/Cinder as our underlying storage provider and Heptio’s Velero for backup and restore of our application
Restic Plugin
Starting with 0.9 version thanks to Restic support, Velero now supports taking backup of almost any type of Kubernetes volume regardless of the underlying storage provider.
Note: Unfortunately it’s not supporting Openstack/Cinder storage class. Let’s see in this blog how to fix
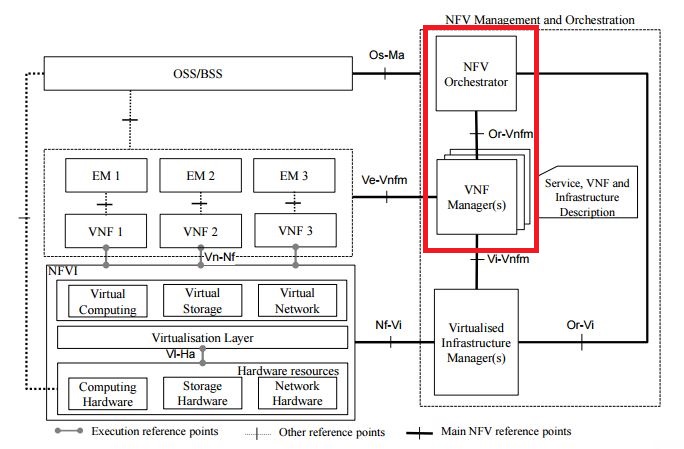
Velero Architecture

Work flow
When you run velero backup create test-backup:
- The Velero client makes a call to the Kubernetes API server to create a
Backupobject. - The
BackupControllernotices the newBackupobject and performs validation. - The
BackupControllerbegins the backup process. It collects the data to back up by querying the API server for resources. - The
BackupControllermakes a call to the object storage service – for example, AWS S3 – to upload the backup file.
How does Restic works with Velero?
Three more Custom Resource Definitions and their associated controllers are introduced for Restic support.
- Restic Repository
- PodVolumeBackup
- PodVolumeRestore
Let’s start Velero !!
Kubernetes Environment Pre-Requisites
- Helm
- Ingress
- Persistent storage ( default storage class set)
Kubernetes Clusters
- Cluster Z: Minio Cluster ( Kubernetes cluster for hosting minio, object storage for backup storage)
- Cluster A: Old Cluster ( Application to migrate from )
- Cluster B: New Cluster ( Application to migrate to )
Deploying Object based storage – minio on Cluster Z
helm install --name minio --namespace minio --set accessKey=minio,secretKey=minio123,persistence.size=100Gi,service.type=NodePort stable/minio1. Login to minio with access key minio & secret key minio123
2. Create a bucket by name kubernetes
Install velero client on Cluster A
wget https://github.com/heptio/velero/releases/download/v1.0.0/velero-v1.0.0-linux-amd64.tar.gz
tar -xvf velero-v1.0.0-linux-amd64.tar.gz
cp velero-v1.0.0-linux-amd64/velero /usr/binCreate velero credentials-velero file ( with minio access key & secret key) on Cluster A
vim credentials-velero [default] aws_access_key_id = minio aws_secret_access_key = minio123
Install velero server on Cluster A
velero install --provider aws --bucket kubernetes --secret-file credentials-velero --use-volume-snapshots=true --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://10.157.249.168:32270 --snapshot-location-config region=minio,s3ForcePathStyle="true",s3Url=http://10.157.249.168:32270 --use-resticInstall Sample application, i will be deploying wordpress on Cluster A
helm install --name wordpress --namespace wordpress --set ingress.enabled=true,ingress.hosts[0].name=wordpress.jaws.jio.com stable/wordpressAnnotate volume to be backuped, since by default cinder storage class doesn’t support snapshotting on Cluster A
kubectl -n wordpress describe pod/wordpress-mariadb-0
...
Volumes:
data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: data-wordpress-mariadb-0
ReadOnly: false
config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: wordpress-mariadb
Optional: false
default-token-r6rpc:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-r6rpc
Optional: false
...
kubectl -n wordpress annotate pod/wordpress-mariadb-0 backup.velero.io/backup-volumes=data,config
kubectl -n wordpress describe pod/wordpress-557589bfbc-7pzqb
...
Volumes:
wordpress-data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: wordpress
ReadOnly: false
default-token-r6rpc:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-r6rpc
Optional: false
...
kubectl -n wordpress annotate pod/wordpress-557589bfbc-7pzqb backup.velero.io/backup-volumes=wordpress-dataCreate a backup on Cluster A
velero backup create wp-backup --snapshot-volumes --include-namespaces wordpressInstall velero client on Cluster B
wget https://github.com/heptio/velero/releases/download/v1.0.0/velero-v1.0.0-linux-amd64.tar.gz
tar -xvf velero-v1.0.0-linux-amd64.tar.gz
cp velero-v1.0.0-linux-amd64/velero /usr/binCreate velero credentials-velero file ( with minio access key & secret key) on Cluster B
vim credentials-velero [default] aws_access_key_id = minio aws_secret_access_key = minio123
Install velero server on Cluster B
velero install --provider aws --bucket kubernetes --secret-file credentials-velero --use-volume-snapshots=true --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://10.157.249.168:32270 --snapshot-location-config region=minio,s3ForcePathStyle="true",s3Url=http://10.157.249.168:32270 --use-resticRestore from backup on Cluster B
velero restore create wordpress-restore --from-backup wp-backup --restore-volumes=trueWait & Verify Restore from backup on Cluster B
kubectl -n wordpress get pods -w kubectl -n wordpress get pods NAME READY STATUS RESTARTS AGE wordpress-68cd5f85c6-gr5vp 1/1 Running 0 2m29s wordpress-mariadb-0 1/1 Running 0 2m24s
Scheduled Backups
Taking a backup manually happens only in an emergency situation or for educational purposes. The real essence of a backup and disaster recovery plan is to have scheduled backups. Ark provides that support in a rather simple manner.
$ velero schedule create daily-wordpress-backup–schedule=”0 10 * * *” –include-namespaces wordpress
Schedule “wordpress-backup” created successfully.
Troubleshooting
In case you are facing any issues regarding the setting up of the kubernetes cluster. Please make sure you have enough physical resources to spin up 3 VM’s. If not you can modify the Vagrantfile as mentioned in the README for the repository to increase/decrease the number of nodes.
For issues related to velero , there are a few commands that may be helpful
$ velero backup describe <backupName>
$ velero backup logs <backupName>
$ velero restore describe <restoreName>
$ velero restore logs <restoreName>
For comprehensive troubleshooting regarding velero, please follow this link.
Cleanup
If you don’t need the cluster anymore, you can go ahead and destroy the cluster
$ cd $HOME/ark-rook-tutorial/k8s-bkp-restore
$ vagrant destroy -f$ rm -rf $HOME/ark-rook-tutorial
Reference
https://github.com/heptio/velero