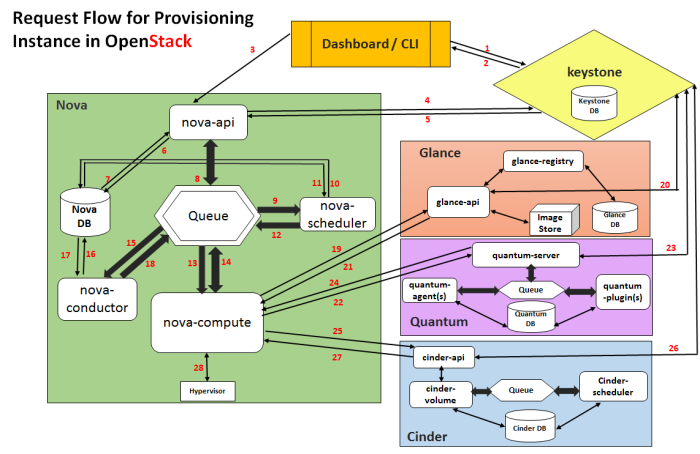
In this article going to see live resizng of Ext File system. It involves two major steps
The extended partition is simply used for swap, so I could easily move it without losing any data.
maestro@ubuntu:~$ sudo fdisk /dev/sda
Command (m for help): p
Disk /dev/sda: 268.4 GB, 268435456000 bytes
255 heads, 63 sectors/track, 32635 cylinders, total 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e49fa
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 192940031 96468992 83 Linux
/dev/sda2 192942078 209713151 8385537 5 Extended
/dev/sda5 192942080 209713151 8385536 82 Linux swap / Solaris
Command (m for help): d
Partition number (1-5): 1
Command (m for help): d
Partition number (1-5): 2
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
Using default value 1
First sector (2048-524287999, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-524287999, default 524287999): 507516925
Command (m for help): p
Disk /dev/sda: 268.4 GB, 268435456000 bytes
255 heads, 63 sectors/track, 32635 cylinders, total 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e49fa
Device Boot Start End Blocks Id System
/dev/sda1 2048 507516925 253757439 83 Linux
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): e
Partition number (1-4, default 2): 2
First sector (507516926-524287999, default 507516926):
Using default value 507516926
Last sector, +sectors or +size{K,M,G} (507516926-524287999, default 524287999):
Using default value 524287999
Command (m for help): p
Disk /dev/sda: 268.4 GB, 268435456000 bytes
255 heads, 63 sectors/track, 32635 cylinders, total 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e49fa
Device Boot Start End Blocks Id System
/dev/sda1 2048 507516925 253757439 83 Linux
/dev/sda2 507516926 524287999 8385537 5 Extended
Command (m for help): n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l
Adding logical partition 5
First sector (507518974-524287999, default 507518974):
Using default value 507518974
Last sector, +sectors or +size{K,M,G} (507518974-524287999, default 524287999):
Using default value 524287999
Command (m for help): p
Disk /dev/sda: 268.4 GB, 268435456000 bytes
255 heads, 63 sectors/track, 32635 cylinders, total 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e49fa
Device Boot Start End Blocks Id System
/dev/sda1 2048 507516925 253757439 83 Linux
/dev/sda2 507516926 524287999 8385537 5 Extended
/dev/sda5 507518974 524287999 8384513 83 Linux
Command (m for help): t
Partition number (1-5): 5
Hex code (type L to list codes): 82
Changed system type of partition 5 to 82 (Linux swap / Solaris)
Command (m for help): p
Disk /dev/sda: 268.4 GB, 268435456000 bytes
255 heads, 63 sectors/track, 32635 cylinders, total 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e49fa
Device Boot Start End Blocks Id System
/dev/sda1 2048 507516925 253757439 83 Linux
/dev/sda2 507516926 524287999 8385537 5 Extended
/dev/sda5 507518974 524287999 8384513 82 Linux swap / Solaris
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
maestro@ubuntu:~$ sudo reboot
maestro@ubuntu:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 91G 86G 12M 100% /
udev 3.9G 4.0K 3.9G 1% /dev
tmpfs 1.6G 696K 1.6G 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 3.9G 144K 3.9G 1% /run/shm
none 100M 16K 100M 1% /run/user
maestro@ubuntu:~$ sudo resize2fs /dev/sda1
resize2fs 1.42.5 (29-Jul-2012)
Filesystem at /dev/sda1 is mounted on /; on-line resizing required
old_desc_blocks = 6, new_desc_blocks = 16
The filesystem on /dev/sda1 is now 63439359 blocks long.
maestro@ubuntu:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 239G 86G 142G 38% /
udev 3.9G 12K 3.9G 1% /dev
tmpfs 1.6G 696K 1.6G 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 3.9G 152K 3.9G 1% /run/shm
none 100M 36K 100M 1% /run/user
Now successfully lively resized file system.